
阿里云今年的年终奖。。。
图解学习网站:
大家好,我是小林。
今年的阿里云年终奖开奖了,除了年终奖之外,还有配长期激励:
绩效3.75:6-7个月左右,P7 拿这个绩效有 30-50 万长期激励,超出区间也是有的,有能拿到 50-60 万,甚至有个例能达到 100 万左右
绩效3.5+:3-4个月左右,好部门 P6 拿这个绩效的有 20-30 万长期激励
绩效3.5:2-3个月左右,有长期现金激励的较少
绩效3.75:6-7个月左右,P7 拿这个绩效有 30-50 万长期激励,超出区间也是有的,有能拿到 50-60 万,甚至有个例能达到 100 万左右
绩效3.5+:3-4个月左右,好部门 P6 拿这个绩效的有 20-30 万长期激励
绩效3.5:2-3个月左右,有长期现金激励的较少
阿里云激励给的确实很足,自然面试难度不低的。
正常来说阿里云的校招面经是 3 轮技术面,不过不少同学面阿里云的时候,经常被加面。
甚至有同学被加到 5 轮技术面,这面试流程可以说是非常长了,只要其中有一面挂了, 直接就前功尽弃了,如果是 5 面挂了,真实太心痛了,不过技术面全部通过之后,hr 面挂人也是见过。。
为什么会加面?加面的目的是什么?我觉得有两个可能。
可能你是前面的面试评价都很优秀,然后再加一面再评估一下给你发普通 offer 还是 ssp offer,因为每个组的 ssp offer 都是有名额的,所以需要谨慎评估。
展开全文
也有可能好几个候选人都进入到 3 面了,可是部门的 hc 不够,不能全部都发 offer,所以再加一面,整体再排序一下,最后择优通过。
这次来看看一位同学阿里云二面的面经,虽然整体问题不算多,但是涉及的知识范围比较广,比如操作系统、计算机网络、JVM、docker、JWT、算法、场景题都涉及了一遍。而且算法还是两道题,还是挺有压力的,整场面试体感还是比较有压力的,时长是超过 1 小时的了。

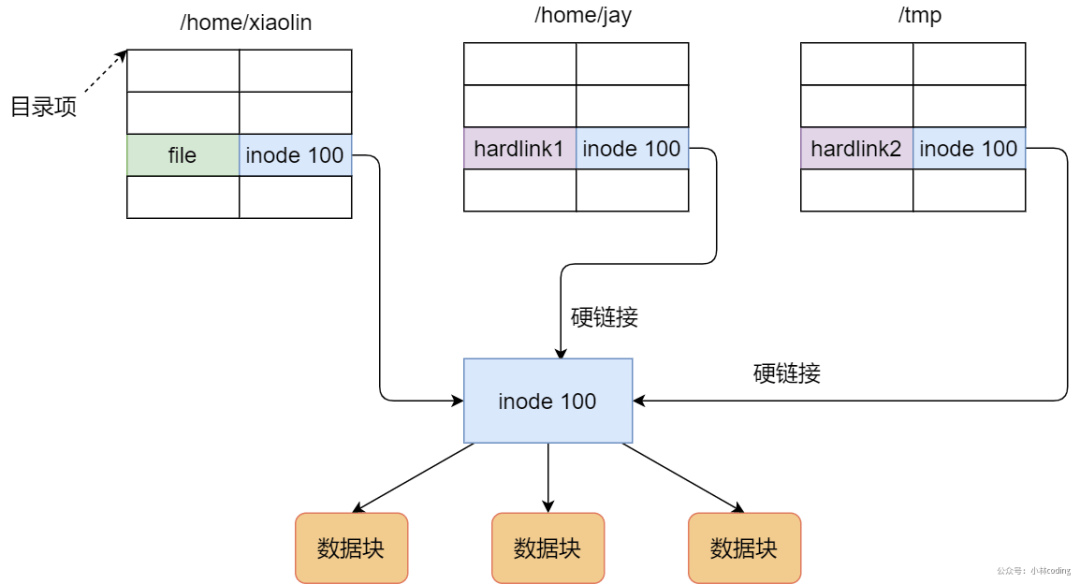
阿里云(二面)1. 软链接与硬链接区别是什么?
有时候我们希望给某个文件取个别名,那么在 Linux 中可以通过硬链接和软链接的方式来实现,它们都是比较特殊的文件,但是实现方式也是不相同的。
硬链接是多个目录项中的「索引节点」指向一个文件,也就是指向同一个 inode,但是 inode 是不可能跨越文件系统的,每个文件系统都有各自的 inode 数据结构和列表,所以硬链接是不可用于跨文件系统的。由于多个目录项都是指向一个 inode,那么只有删除文件的所有硬链接以及源文件时,系统才会彻底删除该文件。
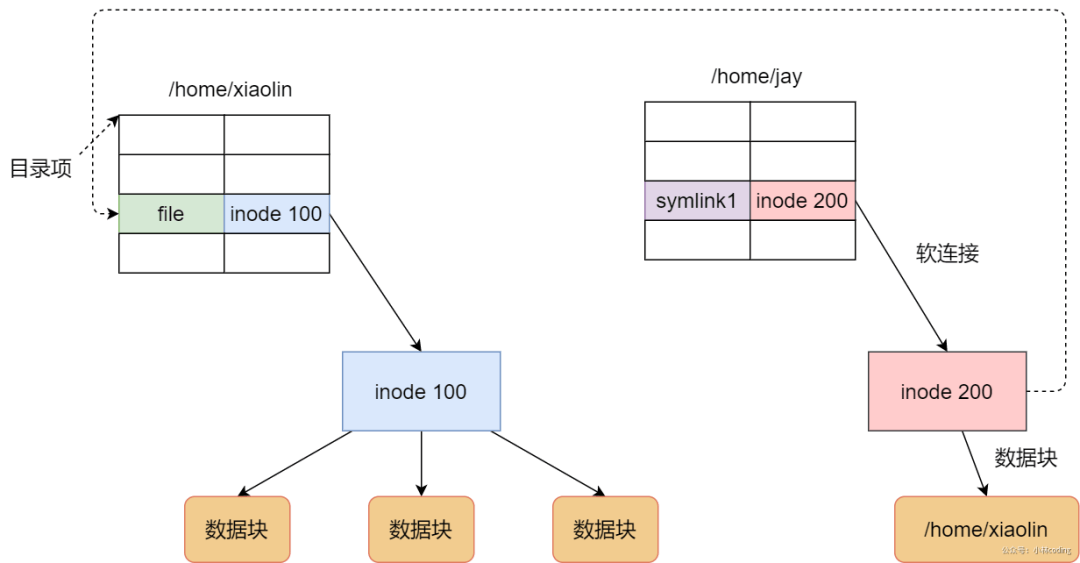
软链接相当于重新创建一个文件,这个文件有独立的 inode,但是这个文件的内容是另外一个文件的路径,所以访问软链接的时候,实际上相当于访问到了另外一个文件,所以软链接是可以跨文件系统的,甚至目标文件被删除了,链接文件还是在的,只不过指向的文件找不到了而已。
2. 僵尸进程与孤儿进程的区别是什么?
僵尸进程是 “死而未僵”,需要父进程回收,孤儿进程是 “父死子存”,会被系统自动收养。
当子进程结束运行(调用exit),但父进程没有通过wait或waitpid等系统调用获取子进程的退出状态信息时,子进程就会变成僵尸进程,这时候在进程列表中显示为Z(Zombie)状态,僵尸进程虽然已经终止,但仍然占用进程表中的一个条目(PCB,进程控制块),直到父进程读取其退出状态,如果大量僵尸进程堆积,会导致系统进程表资源耗尽,无法创建新进程。
当父进程先于子进程结束时,子进程就会变成孤儿进程,孤儿进程会被init(进程 ID 为 1),成为它们的子进程,这时候孤儿进程的父进程 ID(PPID)会被重置为 1,孤儿进程正常运行,不会成为僵尸,因为init会自动回收其退出状态。
当子进程结束运行(调用exit),但父进程没有通过wait或waitpid等系统调用获取子进程的退出状态信息时,子进程就会变成僵尸进程,这时候在进程列表中显示为Z(Zombie)状态,僵尸进程虽然已经终止,但仍然占用进程表中的一个条目(PCB,进程控制块),直到父进程读取其退出状态,如果大量僵尸进程堆积,会导致系统进程表资源耗尽,无法创建新进程。
当父进程先于子进程结束时,子进程就会变成孤儿进程,孤儿进程会被init(进程 ID 为 1),成为它们的子进程,这时候孤儿进程的父进程 ID(PPID)会被重置为 1,孤儿进程正常运行,不会成为僵尸,因为init会自动回收其退出状态。
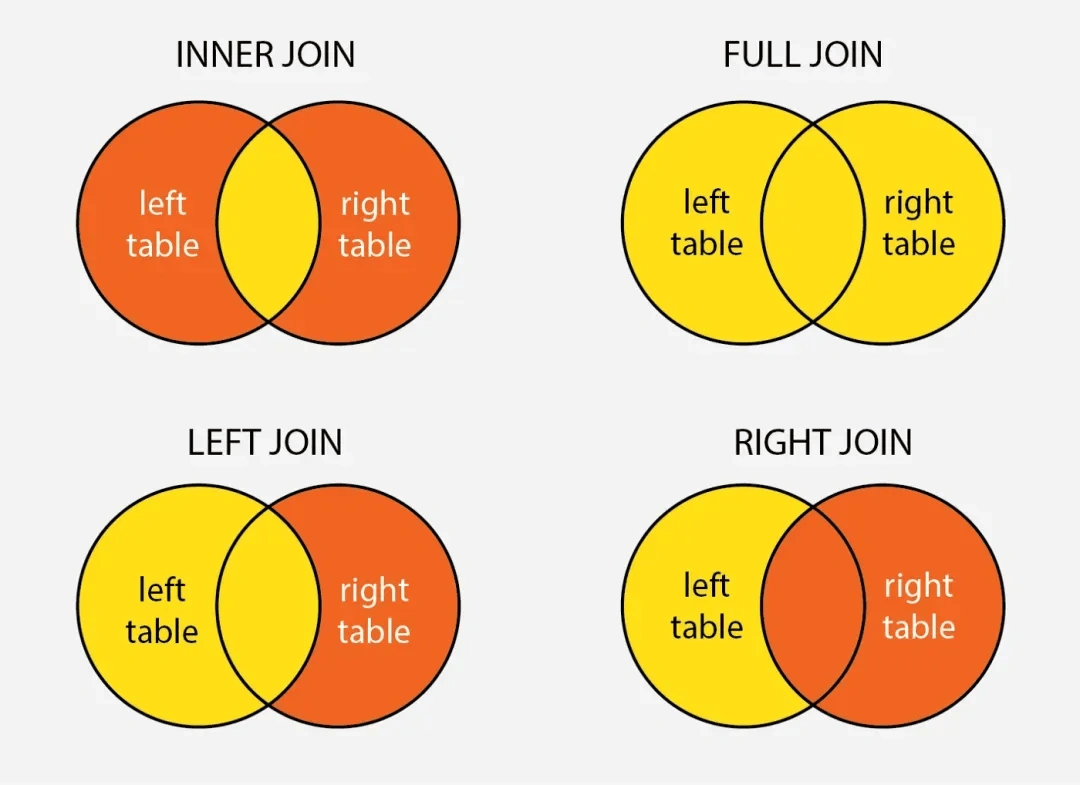
左外连接返回左表中的所有行,即使在右表中没有匹配的行。未匹配的右表列会包含NULL。示例:
SELECTemployees.name, departments.name
FROMemployees
LEFTJOINdepartments
ONemployees.department_id = departments.id;
这个查询返回所有员工及其部门名称,包括那些没有分配部门的员工。
右外连接返回右表中的所有行,即使左表中没有匹配的行。未匹配的左表列会包含NULL。示例:
SELECTemployees.name, departments.name
FROMemployees
RIGHTJOINdepartments
ONemployees.department_id = departments.id;
这个查询返回所有部门及其员工,包括那些没有分配员工的部门。
4. tcp 连接 time wait状态过多的原因是什么?对于请求方和响应方的危害是什么?如何避免?
在 TCP 四次挥手关闭连接时,主动关闭方在发送最后一个 ACK 后会进入 TIME_WAIT 状态,持续时间为2MSL。
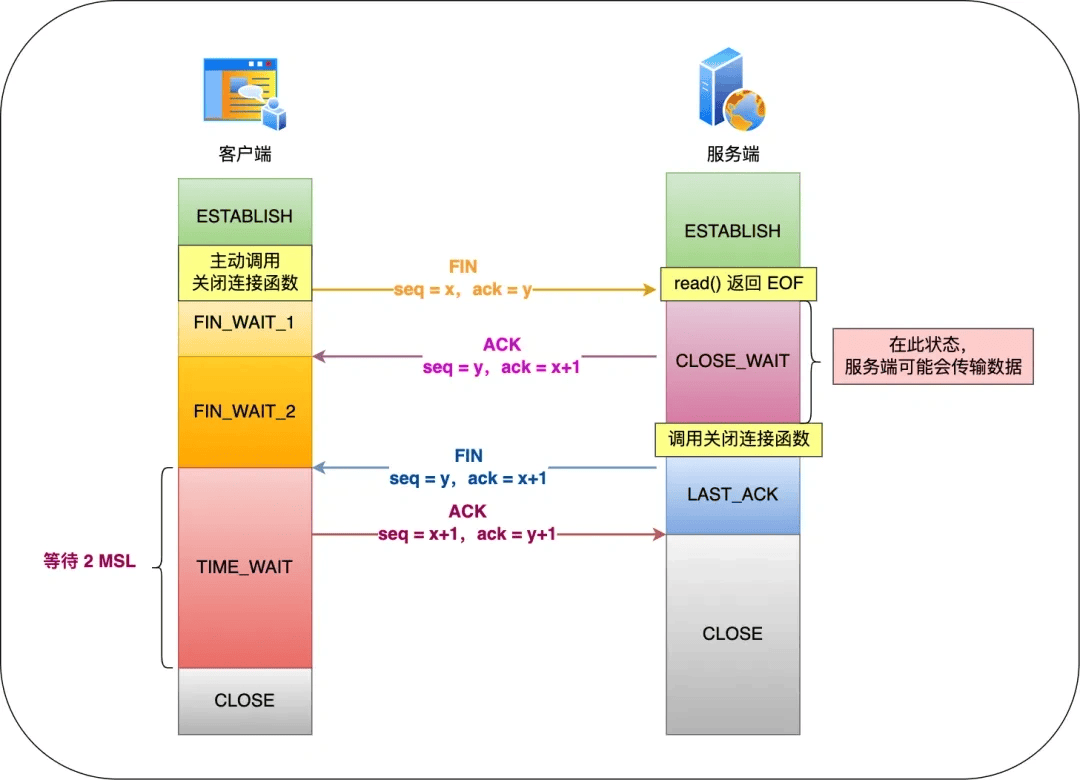
TIME_WAIT状态的主要作用是:
确保最后一个 ACK 到达对端:如果 ACK 丢失,被动关闭方会重发 FIN,TIME_WAIT 状态可以处理这种情况。
防止旧连接的数据包干扰新连接:TIME_WAIT 可以让本次连接的所有数据包在网络中自然消失,避免被新连接复用。
确保最后一个 ACK 到达对端:如果 ACK 丢失,被动关闭方会重发 FIN,TIME_WAIT 状态可以处理这种情况。
防止旧连接的数据包干扰新连接:TIME_WAIT 可以让本次连接的所有数据包在网络中自然消失,避免被新连接复用。
TIME_WAIT 状态过多的原因就是主动关闭连接方频繁关闭 tcp 连接,可能的场景:
并发短连接应用:频繁建立和关闭连接,导致 TIME_WAIT 状态堆积。
长连接未合理使用:应用未复用连接,频繁创建新连接。
系统配置不当:未启用端口复用或快速回收机制。
并发短连接应用:频繁建立和关闭连接,导致 TIME_WAIT 状态堆积。
长连接未合理使用:应用未复用连接,频繁创建新连接。
系统配置不当:未启用端口复用或快速回收机制。
TIME_WAIT 状态过多会引起的危害:
端口资源耗尽:每个TIME_WAIT连接会占用一个本地端口,如果端口耗尽,新连接会因无法分配端口而失败(错误如Cannot assign requested address)。
内存和文件描述符占用:每个连接在内核中需要维护数据结构,可能影响系统整体性能。
性能下降:内核需要管理大量TIME_WAIT连接,增加 CPU 和内存开销。
端口资源耗尽:每个TIME_WAIT连接会占用一个本地端口,如果端口耗尽,新连接会因无法分配端口而失败(错误如Cannot assign requested address)。
内存和文件描述符占用:每个连接在内核中需要维护数据结构,可能影响系统整体性能。
性能下降:内核需要管理大量TIME_WAIT连接,增加 CPU 和内存开销。
避免 TIME_WAIT 过多的方式:
应用层的优化:尽量使用长连接的方式,少频繁建立和关闭连接的开销。
架构层的优化::尽量让服务器作为被动关闭方(通过协议设计控制 FIN 发送时机),还可以用连接池技术复用已建立的连接,减少新建连接的开销。
系统参数的优化:客户端启用启用TIME_WAIT状态的连接复用的功能
应用层的优化:尽量使用长连接的方式,少频繁建立和关闭连接的开销。
架构层的优化::尽量让服务器作为被动关闭方(通过协议设计控制 FIN 发送时机),还可以用连接池技术复用已建立的连接,减少新建连接的开销。
系统参数的优化:客户端启用启用TIME_WAIT状态的连接复用的功能
sysctl -w net.ipv4.tcp_tw_reuse=1
5. 服务器出现大量close wait状态的原因?
在 TCP 四次挥手过程中:
被动关闭方收到对方的 FIN 包后,会回复 ACK 并进入CLOSE_WAIT状态
此时被动关闭方需主动调用 close 发送 FIN 包,才能完成连接关闭
被动关闭方收到对方的 FIN 包后,会回复 ACK 并进入CLOSE_WAIT状态
此时被动关闭方需主动调用 close 发送 FIN 包,才能完成连接关闭
CLOSE_WAIT是被动关闭方的中间状态,正常情况下应短暂存在并快速过渡到LAST_ACK状态。
所以大量出现CLOSE_WAIT状态的核心原理是应用程序未正确关闭连接,比如代码层面的问题
未调用close或shutdown关闭 Socket 连接
资源释放逻辑缺失(如 try-catch 中未关闭连接)
未调用close或shutdown关闭 Socket 连接
资源释放逻辑缺失(如 try-catch 中未关闭连接)
排查的方式重点检查以下场景:
数据库连接、 编程的资源释放逻辑
异步任务、定时任务中的连接关闭处理
异常捕获块(try-catch-finally)中的资源释放是否完整
数据库连接、 编程的资源释放逻辑
异步任务、定时任务中的连接关闭处理
异常捕获块(try-catch-finally)中的资源释放是否完整
类从被加载到虚拟机内存开始,到卸载出内存为止,它的整个生命周期包括以下 7 个阶段:
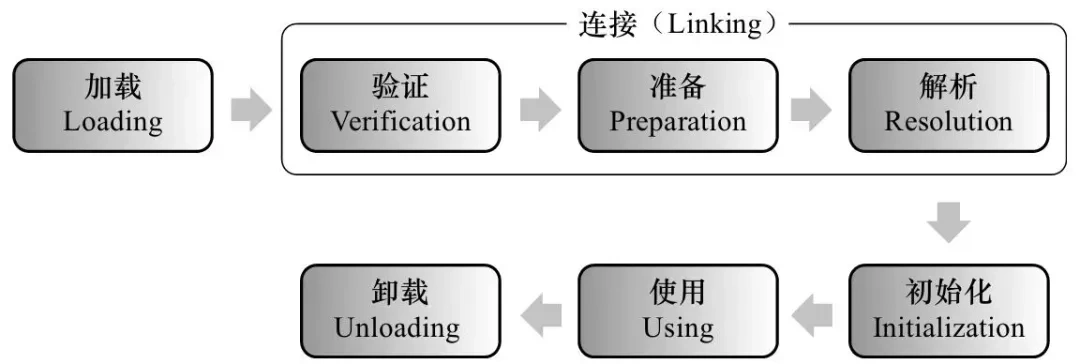
加载:通过类的全限定名(包名 + 类名),获取到该类的.class文件的二进制字节流,将二进制字节流所代表的静态存储结构,转化为方法区运行时的数据结构,在内存中生成一个代表该类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口
连接:验证、准备、解析 3 个阶段统称为连接。
验证:确保class文件中的字节流包含的信息,符合当前虚拟机的要求,保证这个被加载的class类的正确性,不会危害到虚拟机的安全。验证阶段大致会完成以下四个阶段的检验动作:文件格式校验、元数据验证、字节码验证、符号引用验证
准备:为类中的静态字段分配内存,并设置默认的初始值,比如int类型初始值是0。被final修饰的static字段不会设置,因为final在编译的时候就分配了
解析:解析阶段是虚拟机将常量池的「符号引用」直接替换为「直接引用」的过程。符号引用是以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用的时候可以无歧义地定位到目标即可。直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄,直接引用是和虚拟机实现的内存布局相关的。如果有了直接引用, 那引用的目标必定已经存在在内存中了。
初始化:初始化是整个类加载过程的最后一个阶段,初始化阶段简单来说就是执行类的构造器方法,要注意的是这里的构造器方法并不是开发者写的,而是编译器自动生成的。
使用:使用类或者创建对象
卸载:如果有下面的情况,类就会被卸载:1. 该类所有的实例都已经被回收,也就是java堆中不存在该类的任何实例。2. 加载该类的ClassLoader已经被回收。 3. 类对应的java.lang.Class对象没有任何地方被引用,无法在任何地方通过反射访问该类的方法。
加载:通过类的全限定名(包名 + 类名),获取到该类的.class文件的二进制字节流,将二进制字节流所代表的静态存储结构,转化为方法区运行时的数据结构,在内存中生成一个代表该类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口
连接:验证、准备、解析 3 个阶段统称为连接。
验证:确保class文件中的字节流包含的信息,符合当前虚拟机的要求,保证这个被加载的class类的正确性,不会危害到虚拟机的安全。验证阶段大致会完成以下四个阶段的检验动作:文件格式校验、元数据验证、字节码验证、符号引用验证
准备:为类中的静态字段分配内存,并设置默认的初始值,比如int类型初始值是0。被final修饰的static字段不会设置,因为final在编译的时候就分配了
解析:解析阶段是虚拟机将常量池的「符号引用」直接替换为「直接引用」的过程。符号引用是以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用的时候可以无歧义地定位到目标即可。直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄,直接引用是和虚拟机实现的内存布局相关的。如果有了直接引用, 那引用的目标必定已经存在在内存中了。
验证:确保class文件中的字节流包含的信息,符合当前虚拟机的要求,保证这个被加载的class类的正确性,不会危害到虚拟机的安全。验证阶段大致会完成以下四个阶段的检验动作:文件格式校验、元数据验证、字节码验证、符号引用验证
准备:为类中的静态字段分配内存,并设置默认的初始值,比如int类型初始值是0。被final修饰的static字段不会设置,因为final在编译的时候就分配了
解析:解析阶段是虚拟机将常量池的「符号引用」直接替换为「直接引用」的过程。符号引用是以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用的时候可以无歧义地定位到目标即可。直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄,直接引用是和虚拟机实现的内存布局相关的。如果有了直接引用, 那引用的目标必定已经存在在内存中了。
初始化:初始化是整个类加载过程的最后一个阶段,初始化阶段简单来说就是执行类的构造器方法,要注意的是这里的构造器方法并不是开发者写的,而是编译器自动生成的。
使用:使用类或者创建对象
卸载:如果有下面的情况,类就会被卸载:1. 该类所有的实例都已经被回收,也就是java堆中不存在该类的任何实例。2. 加载该类的ClassLoader已经被回收。 3. 类对应的java.lang.Class对象没有任何地方被引用,无法在任何地方通过反射访问该类的方法。
基于 Namespace 的视图隔离:Docker利用Linux命名空间(Namespace)来实现不同容器之间的隔离。每个容器都运行在自己的一组命名空间中,包括PID(进程)、网络、挂载点、IPC(进程间通信)等。这样,容器中的进程只能看到自己所在命名空间内的进程,而不会影响其他容器中的进程。
基于 cgroups 的资源隔离:cgroups 是Linux内核的一个功能,允许在进程组之间分配、限制和优先处理系统资源,如CPU、内存和磁盘I/O。它们提供了一种机制,用于管理和隔离进程集合的资源使用,有助于资源限制、工作负载隔离以及在不同进程组之间进行资源优先处理。
基于 Namespace 的视图隔离:Docker利用Linux命名空间(Namespace)来实现不同容器之间的隔离。每个容器都运行在自己的一组命名空间中,包括PID(进程)、网络、挂载点、IPC(进程间通信)等。这样,容器中的进程只能看到自己所在命名空间内的进程,而不会影响其他容器中的进程。
基于 cgroups 的资源隔离:cgroups 是Linux内核的一个功能,允许在进程组之间分配、限制和优先处理系统资源,如CPU、内存和磁盘I/O。它们提供了一种机制,用于管理和隔离进程集合的资源使用,有助于资源限制、工作负载隔离以及在不同进程组之间进行资源优先处理。
bridge和host是两种常用的网络模式,它们的主要区别如下:
在Bridge模式下,Docker会为每个容器创建一个虚拟网络接口,并分配一个独立的IP地址。容器之间可以通过桥接网络进行通信,也可以通过宿主机进行网络访问。bridge模式的优点是容器之间互相隔离、每个容器都有自己独立的IP地址、安全性较好。此外,bridge模式允许我们通过网络连接容器、方便容器之间的通信。缺点是相对于Host模式,bridge模式的网络性能要稍差一些,因为容器之间的网络通信需要经过额外的网络转发和封装。
在Host模式下、容器与宿主机共享网络命名空间,容器直接使用宿主机的网络资源。这意味着容器可以绑定宿主机的IP地址和端口,使得容器中运行的应用程序可以直接访问宿主机网络上的服务。Host模式的优点是网络性能较好,因为容器直接使用宿主机的网络资源,避免了额外的网络转发和封装。但是,Host模式下容器与宿主机共享网络命名空间,容器的网络隔离性较差,容器中的应用程序可能会直接访问到宿主机上的服务,增加了安全风险。
在Bridge模式下,Docker会为每个容器创建一个虚拟网络接口,并分配一个独立的IP地址。容器之间可以通过桥接网络进行通信,也可以通过宿主机进行网络访问。bridge模式的优点是容器之间互相隔离、每个容器都有自己独立的IP地址、安全性较好。此外,bridge模式允许我们通过网络连接容器、方便容器之间的通信。缺点是相对于Host模式,bridge模式的网络性能要稍差一些,因为容器之间的网络通信需要经过额外的网络转发和封装。
在Host模式下、容器与宿主机共享网络命名空间,容器直接使用宿主机的网络资源。这意味着容器可以绑定宿主机的IP地址和端口,使得容器中运行的应用程序可以直接访问宿主机网络上的服务。Host模式的优点是网络性能较好,因为容器直接使用宿主机的网络资源,避免了额外的网络转发和封装。但是,Host模式下容器与宿主机共享网络命名空间,容器的网络隔离性较差,容器中的应用程序可能会直接访问到宿主机上的服务,增加了安全风险。
用的是 jwt 来做鉴权的。
在传统的基于会话和Cookie的身份验证方式中,会话信息通常存储在服务器的内存或数据库中。但在集群部署中,不同服务器之间没有共享的会话信息,这会导致用户在不同服务器之间切换时需要重新登录,或者需要引入额外的共享机制(如Redis),增加了复杂性和性能开销。
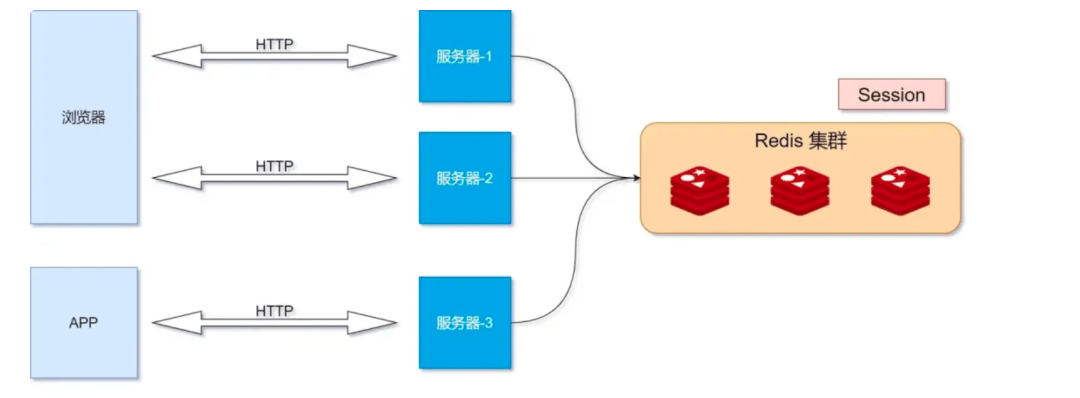
而JWT令牌通过在令牌中包含所有必要的身份验证和会话信息,使得服务器无需存储会话信息,从而解决了集群部署中的身份验证和会话管理问题。当用户进行登录认证后,服务器将生成一个JWT令牌并返回给客户端。客户端在后续的请求中携带该令牌,服务器可以通过对令牌进行验证和解析来获取用户身份和权限信息,而无需访问共享的会话存储。
由于JWT令牌是自包含的,服务器可以独立地对令牌进行验证,而不需要依赖其他服务器或共享存储。这使得集群中的每个服务器都可以独立处理请求,提高了系统的可伸缩性和容错性。
10. JWT的组成部分以及原理是什么?
JWT令牌由三个部分组成:头部(Header)、载荷(Payload)和签名(Signature)。其中,头部和载荷均为JSON格式,使用Base64编码进行序列化,而签名部分是对头部、载荷和密钥进行签名后的结果。
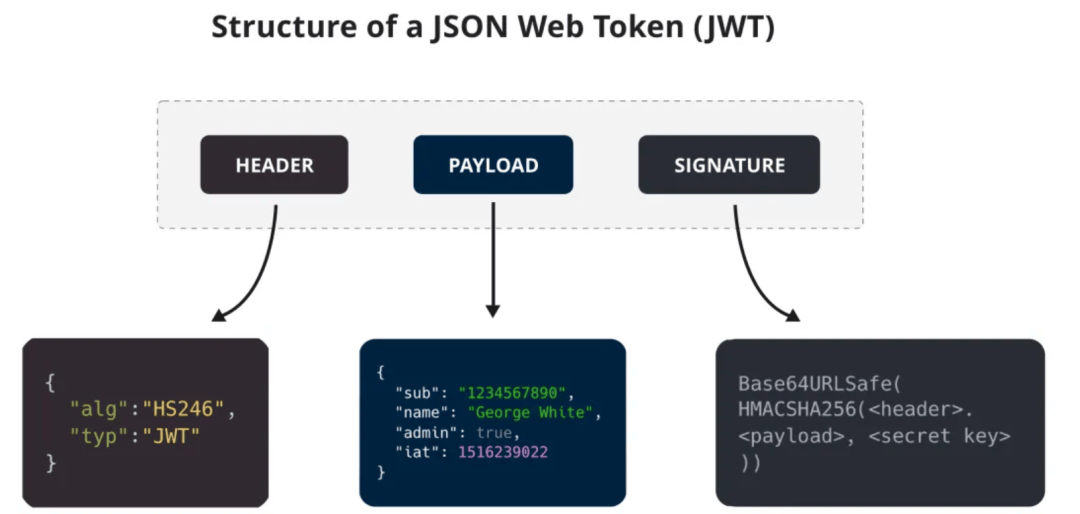
JWT的工作原理:
用户认证:用户登录时,服务器验证凭证,验证通过后,服务器生成 JWT 并返回给客户端
客户端存储:JWT 通常存储在localStorage或cookie中,后续请求在
服务端验证:服务器接收 JWT 后,解码 Header 获取签名算法,使用相同算法和密钥重新计算签名,比对两个签名是否一致,验证 Payload 中的exp等声明
数据提取:验证通过后,服务器从 Payload 中提取用户信息,无需查询数据库即可完成授权
用户认证:用户登录时,服务器验证凭证,验证通过后,服务器生成 JWT 并返回给客户端
客户端存储:JWT 通常存储在localStorage或cookie中,后续请求在
服务端验证:服务器接收 JWT 后,解码 Header 获取签名算法,使用相同算法和密钥重新计算签名,比对两个签名是否一致,验证 Payload 中的exp等声明
数据提取:验证通过后,服务器从 Payload 中提取用户信息,无需查询数据库即可完成授权
分布式部署下的的日志文件如何进行收集和分析
如何设计一个高可用的分布式系统
在线部署项目或者更新项目的时候可能会导致某些节点暂时不可用,如何解决
分布式部署下的的日志文件如何进行收集和分析
如何设计一个高可用的分布式系统
在线部署项目或者更新项目的时候可能会导致某些节点暂时不可用,如何解决
手撕1:图上能同时流向大西洋与太平洋的坐标
手撕2:岛屿数量;
手撕1:图上能同时流向大西洋与太平洋的坐标
手撕2:岛屿数量;








评论